Upon completing Alteryx Weekly Challenge #79, I had one remaining related sub-challenge that I wanted to solve with Alteryx. That was to find the nearest prime to a given number n based on a lookup table, but one that had memory. So that if a number was larger than the largest prime in the lookup table, Alteryx would build the lookup table up to n’s nearest prime neighbour (although only from the largest prime in the table, and not recalculate any values). The new primes would then be unioned to the existing lookup table for future lookups. This method should be more efficient than calculating values each time. I found that even with relatively large lookup tables (up to n=20,000), Alteryx easily handles number comparisons (i.e. I did not have to break the table down into smaller chunks for Alteryx to check against).
Some stumbling blocks
 My first thought with this sub-challenge was to leverage Alteryx’s built-in cache tool, which seems ideally suited to the purpose. When I had trouble getting it working, I moved things one level down and ran it by writing the lookup table to a .yxdb (an external file in Alteryx’s own format). This gave me more control over where it was being written to, but a file opening conflict error persisted. I was able to solve this with a block until done tool. Once everything was working using the .yxdb output, I went back to the cache tool.
My first thought with this sub-challenge was to leverage Alteryx’s built-in cache tool, which seems ideally suited to the purpose. When I had trouble getting it working, I moved things one level down and ran it by writing the lookup table to a .yxdb (an external file in Alteryx’s own format). This gave me more control over where it was being written to, but a file opening conflict error persisted. I was able to solve this with a block until done tool. Once everything was working using the .yxdb output, I went back to the cache tool.
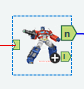
I found that my Prime macro only generated primes up to n, however the nearest prime may actually be larger than n. In order to address this, I ended up building out the workflow to find primes up to n, then taking the largest prime up to n, adding 1 to that, and finding the next prime. This second macro only outputs one row (n and the largest prime after n). This gets unioned with the results from the earlier workflow (all primes up to n) and added to the lookup table.
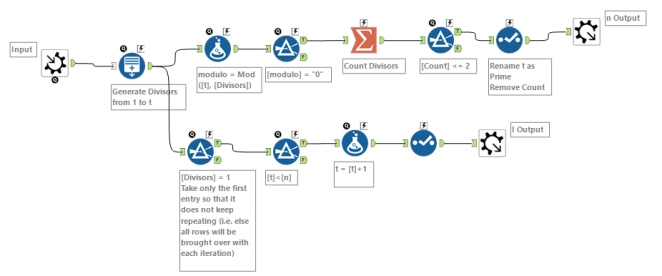
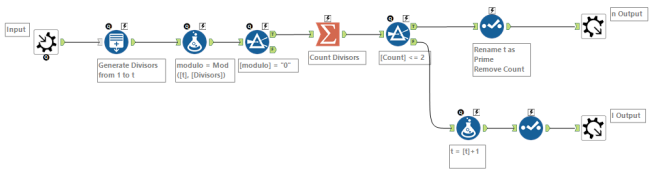
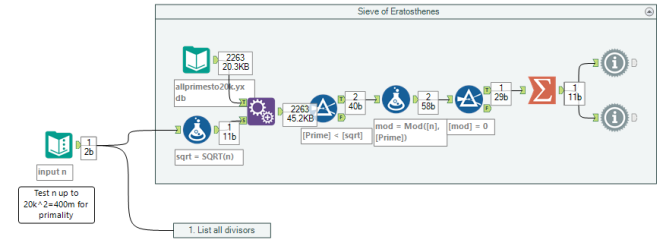
Sieve of Erathosthenes
When parts of the workflow weren’t working (mostly the macros), it helped to take that part of the workflow out into another workflow and just tinker with that section, then copy and paste it back into the main workflow when I could get it to do what I wanted. With one of those experiments, I found myself generating all primes up to 20,000 (in part to test how long a workflow would take to do this). When I then read up about the Sieve of Eratosthenes in some background reading, I thought this would be a(nother) perfect challenge for Alteryx, particularly that last line!
6.2. Sieve of Eratosthenes
A process named for a Greek mathematician of the third century BCE, the algorithm is a trial and error based method for testing a number for primality. If no prime greater than 2 and smaller than the square root of the number being tested divides that number (is a factor of the number) then the number is prime.
The sieve is slow and becomes computationally expensive and time consuming as the magnitude of the number being tested increases.
Source: https://www.sans.org/reading-room/whitepapers/vpns/prime-numbers-public-key-cryptography-969
With my lookup table going up to 20,000, this meant that I could test for primality of numbers of up to 20,000^2=400,000,000. Indeed, it was able to return whether numbers near to 400,000,000 were prime or not within less than 1 second. I have not continued to test how large the numbers would need to get to substantially slow down the workflow. Additionally, the processing admittedly largely comes in generating the prime numbers up to 20,000 in the lookup table.